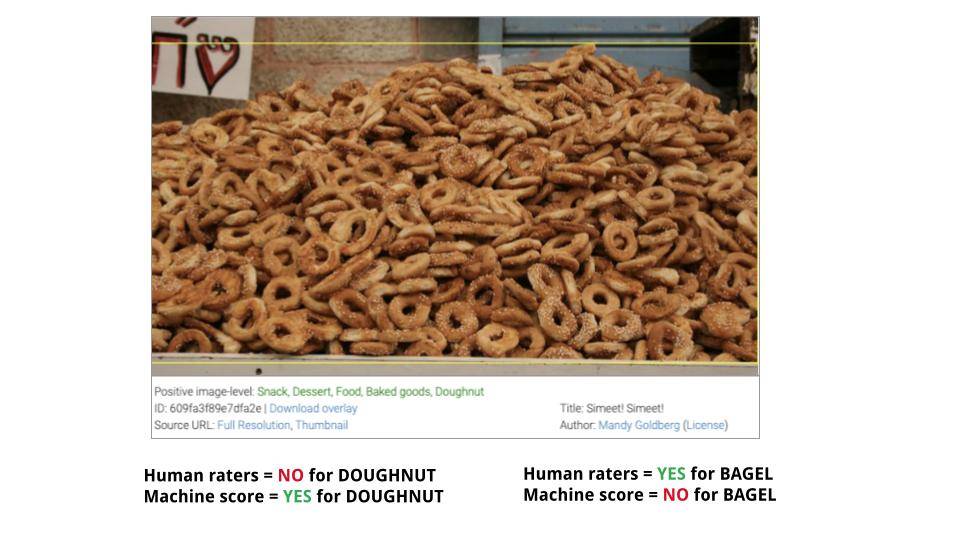
Machine learning may border on magic, and provide many of the biggest technical benefits we've enjoyed in the last decade, but it has plenty of "weak spots." One of Google's biggest concerns is that models are often trained using example data that's too easy to interpret, making them unprepared for the greater ambiguity of the real world. Case in point: Telling a donut from a bagel.
It's an easy mistake to make, they share so many characteristics: Both are round, they've got a hole in them, and sometimes a visible texture on the top. It may even be something you or I could have difficulty recognizing the difference between in the right circumstance, but it doesn't actually end up being that much of an issue for us, often thanks to context.
It's a fundamental problem based on how we train machine learning models. Data sets for things like image recognition, as an example, are often pruned to contain images that are intentionally easy to discern, with a clear focus on the subject. The hope is clearly that from these tightly-focused examples, the model will gain the ability to recognize images in context, but that doesn't always pan out, and it leaves them vulnerable when examining real-world examples that may not be so forgiving. But by far, the hardest part is determining exactly what these models don't know — their "weak spots."
There are ultimately two categories of weak spots, with names only software engineers could have come up with: known unknowns and unknown unknowns. Broadly speaking, a known unknown is when the model itself reports low confidence in its answer — i.e., it knows it doesn't know what it's looking at. And that's actually pretty easy to fix. If the model can be confident in its lack of confidence, it can set that image aside for a human answer. Unknown unknowns are the tricky ones to address because the model ends up utterly confident in its wrong answer. That's not something you can self-correct in the same way.
Unknown unknowns also take a few different forms. For example, an image can be intentionally manipulated in subtle ways to trick a model into making a mistake, as in the case of the panda you see just above. A little bit of noise, invisible to our own human eyes, can introduce details a model might pick up on to incorrectly classify it — probably something that is further exaggerated if a model is over-trained on a publicly available example data set. But that's a result of intentional action. It's real-world examples that have researchers more concerned, things like normal photos you or I might take of our dinner or nature that end up being misclassified with extreme confidence.
Unknown unknowns can be further classified as "rare," in the case of things that are so obscure a model may not have been trained on them (like specific dog breeds); "tricky," if the framing, angle, or positions might be confusing, but which context immediately makes clear to a human observer (a donut is more likely to be frosted or powdered, a dog probably wouldn't be found up a tree, etc.); or both "rare" and "tricky" if both are combined (like with a racecar on a track, viewed at an unusual angle through the shimmer of the hot surface). There are a surprising number of ways a machine learning model can be confidently wrong.
Potential "unknown unknowns" from the Open Images Dataset.
To that end, Google is opening a challenge. ML researchers, software developers, and even enthusiasts willing to put in a bit of work are invited to select images from the Open Images Dataset from 24 target labels to find real-world examples of these unknown unknowns. More details, including instructions, are available at the CATS4ML site, together with a presentation that explains these same concepts in better detail.
Again, this isn't for your average consumer, or even me. Google's looking for developers and researchers to participate, and there are plenty of rules for how you have to make your submissions. But machine learning enthusiasts or Android developers looking to expand their horizons a little while we're all stuck inside might be interested in taking a look. There's a whole scoring system, and though there aren't any prizes, Google will even crown a "winner." The challenge closes on April 30th, 2021.
Source: Google, CATS4ML Challenge