
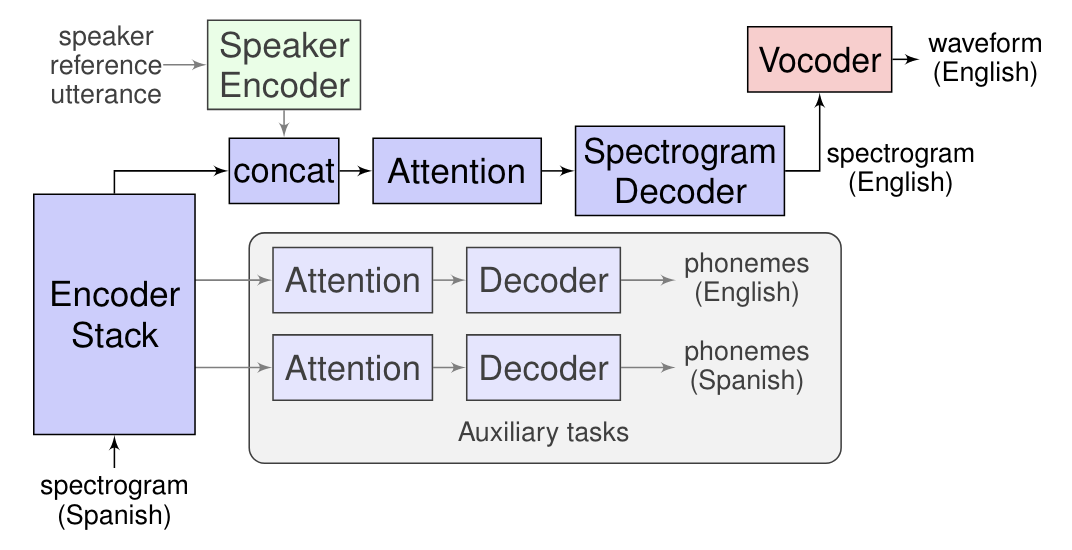
Interpreting and translating live speech is much trickier than simply processing written text. Indeed, unlike human brains, machines would typically need to go through three separate phases to convert oral communication from one language to another. Initially, speech would need to be interpreted by the machine and transcribed into text, which would then be translated into the target dialect, before being fed into a text-to-speech engine to be spoken out loud. Although this cascaded process is transparent for the user and relatively fast, Google is working on a more natural speech-to-speech method it called Translatotron, which doesn't need intermediate processing for translation.
{kind=link}

Live speech interpretation is not something new, Google has already made the feature available into its Translate app since 2011 and recently extended it to Assistant, and Microsoft took this further by allowing live speech translation into Skype conversations. However, these features typically use cascade processing to get the job done. As direct speech-to-speech interpretation eliminates intermediaries, it works faster, reduces interpretation errors that could arise during conversion, and can even ignore words that don't need to be translated. What's also impressive is that Translatotron can retain the original speaker's voice in the target language, making it sound more natural.
In reality, this experiment is still work in progress, albeit promising. For instance, the current results are still outperformed by traditional cascade translation, with some of them being completely unintelligible. Also, while Translatotron can mimic the original speaker's voice, it sounds very robotic, unnatural, and slow. Let's keep in mind that direct speech-to-speech translation is still in its early development stages, but it's encouraging and could make it easier to break language barriers.
Source: Google Blog
Alternate title: 'Tronslation' is about to get better with direct speech-to-speech interpretation