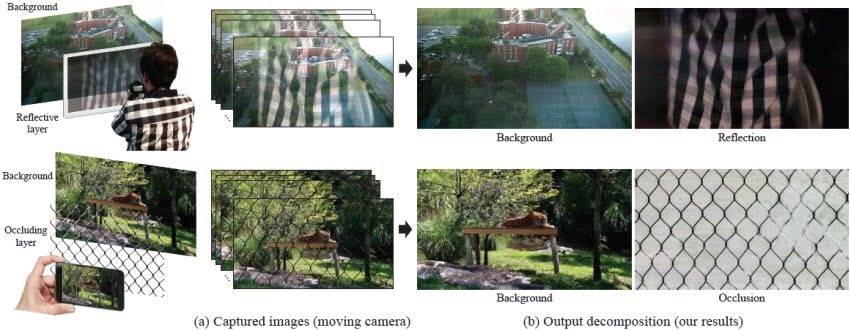
If there's one thing we've learned from Google's various camera and photo products lately, it's that the company is focusing on using some pretty crazy technology to make your image-capture and sharing experience more automagical. Next on Google's list? Annoying reflections and foreground obstructions that make your pictures kind of terrible. Specifically, things like cyclone fences and reflections in windows or other glass. Basically, it's best to just visualize it.
Google and MIT teamed up on this technology, and they'll present a paper on it at the Siggraph 2015 conference this month. Here's a closer look at the process on a panorama photo.
As you can see, the photo has some very obvious reflections, and they do legitimately pretty much ruin the picture. Now, with the cleanup technology, this photo can actually be corrected. And I mean really corrected - the difference is absolutely striking.
If you look closely, there is still some occasional strangness in the corrected image, but it's hugely better than the original and eliminates almost all of the reflected objects. This process is also completely automatic - the user only has to capture the image, there is nothing to select, highlight, or control (unlike many of the more basic object removal features in smartphone cameras).
How's it work? The devil, as always, is in the details. This technology requires multiple frames (5-7) to be captured at multiple relative angles, because obviously it does: the computer has to be able to derive what the image should look like in order for it to make the necessary corrections. A single frame doesn't provide the comparative data points that would be required for this. The researchers suggest in the video below that a few seconds of capture should be enough, though it's not clear how much movement is necessary in order for it to get the amount of contrasting data points it needs to function effectively.
As for implementations, that's not discussed. Certainly, this is something Google would be very interested in using, both on Android and Google Photos, but it's not clear how much computational power is necessary for it to be effective. If the answer is "a lot," that means it could be limited to a cloud-based processing service like Google Photos. If the answer is just "some," then maybe an on-device implementation could happen.
I think on the capture side of things, it's possible this might not be very hard to implement pretty seamlessly if they can get the amount of footage required down to a few seconds. The camera could buffer a small amount of video in memory continuously while the viewfinder is active, and then when the shutter is pressed, use that buffered footage to construct the de-obstructed photo.
There's also a video which explains how the technology works in more detail, which you can see below.
[EMBED_YT]https://www.youtube.com/watch?t=374&v=xoyNiatRIh4
[/EMBED_YT]
You can check out the web page for the Siggraph presentation here, and there's a link to the actual paper over on MIT's site here (warning: it's a 32MB PDF) which contains copious amounts of math and physics that I do not understand.
Source: Google Via: TechCrunch